
W związku z ograniczaniem przez przeglądarki obsługi plików cookie 3rd party („pliki cookie innych firm”), w Chrome przygotowano zestaw funkcji pod nazwą Privacy Sandbox, które mają zastąpić 3rd party cookies i umożliwią realizację uzasadnionych celów, do których były one wykorzystywane ? jednocześnie chroniąc prywatność użytkownika.
Prace nad tą technologią przeciągały się, a kolejne terminy jej oddania do użytku były wielokrotnie przesuwane. Wdrażanie Privacy Sandbox w Chrome rozpoczęło się w styczniu 2024 roku u 1% użytkowników, z perspektywą pełnej adopcji z początkiem 2025 roku.
W lipcu 2024 roku firma Google ogłosiła, że w świetle wyników pilotażu Privacy Sandbox, a także opóźnień w implementacji Privacy Sandbox przez firmy sektora reklamowego oraz zgłaszanych przez nich zastrzeżeń ? rezygnuje z całkowitego wycofania 3rd party cookies. W zamian za to, użytkownicy Chrome uzyskają możliwość łatwego wyboru poziomu prywatności i zakresu przetwarzanych danych.
Niezależnie od ostatecznej daty wycofania 3rd party cookies z Chrome, zważywszy na to, co się wydarzyło wcześniej w Safari i innych przeglądarkach, technologie 3rd party cookies będą coraz bardziej spychane na margines. Całkowite wycofanie 3rd party cookies z Chrome będzie oznaczało de facto koniec tej technologii.
Warto podkreślić, że wycofanie 3rd party cookies to nie koniec cookies jako takich. Ciasteczka 1st party pozostają, bo trudno sobie wyobrazić funkcjonowanie usług cyfrowych bez jakiejś formy 1st party storage.
Czym się różnią pliki cookie 3rd party od 1st party?
Pliki cookie 1st i 3rd party różnią się jedynie sposobem zapisywania i odczytywania zawartych w nich danych.
| 1st party cookie | 3rd party cookie |
|---|---|
| Utworzone przez stronę, którą odwiedzasz i przypisane do jej domeny. | Utworzone przez stronę (serwer) z innej domeny, niż odwiedzana strona, np. przez skrypt śledzący. |
| Tylko ta strona (w tej domenie) w może odczytać ich zawartość. | Może być odczytane przez skrypt domeny, z której pochodzi, umieszczony na dowolnej stronie. |
| Przykład: Strona adequate.digital tworzy cookie zawierające identyfikator użytkownika do celów statystycznych i odnotowuje w systemie analitycznym źródło tej wizyty. Dzięki cookie, przy kolejnej wizycie na stronie, system analityczny wie, że jest to ten sam, powracający użytkownik i może określić skąd pierwotnie został on pozyskany. Inne strony nie mają do niego dostępu. | Przykład: Skrypt google.com umieszczony na stronie adequate.digital zostawia identyfikator użytkownika do celów reklamowych i wysyła do Google informację o wizycie na stronie adequate.digital. Dzięki temu, skrypt google.com umieszczony na stronie onet.pl może wyświetlić temu użytkownikowi reklamę remarketingową kierowaną do osób, które wcześniej odwiedziły adequate.digital. |
„Skutkiem ubocznym” właściwości 3rd party cookies jest możliwość zbierania przez serwer, który je utworzył, historii odwiedzanych przez użytkownika stron oraz innych szczegółów tych wizyt. Przykładem może być cookie Facebooka, zapisywane i odczytywane przez piksel śledzący lub inne, popularne swego czasu widżety (np. przycisk „lubię to” lub „udostępnij na Facebooku”) umieszczone na wielu stronach. Dzięki temu Facebook zbiera historię wizyt i profiluje użytkowników na masową skalę do celów reklamowych.
Co zawiniły 3rd party cookies?
3rd party cookies, małe pliki służące do zapisywania niewielkich porcji informacji (najczęściej prostych zmiennych lub identyfikatorów) wspierały działanie takich funkcji jak ochrona przed spamem i botami, liczne funkcje stron www, pomiar skuteczności wyświetleń reklamy oraz remarketing i kierowanie reklam w oparciu o zainteresowania.
Stanowią one jednak zagrożenie dla prywatności, ponieważ pozwalają na niemal nieograniczone zbieranie informacji o naszej aktywności w sieci oraz ich wymianę między niepowiązanymi z sobą stronami.
Wyobraź sobie, że kupujesz w sklepie internetowym sejf z dostawą do domu, a następnie w kantorze online zamawiasz sztabki złota, po czym wykupujesz wycieczkę dookoła świata. A co powiesz na to, że jest ktoś, kto te trzy informacje może połączyć i jeszcze zna Twój adres, a Ty nawet nie wiesz, kim ta osoba jest?
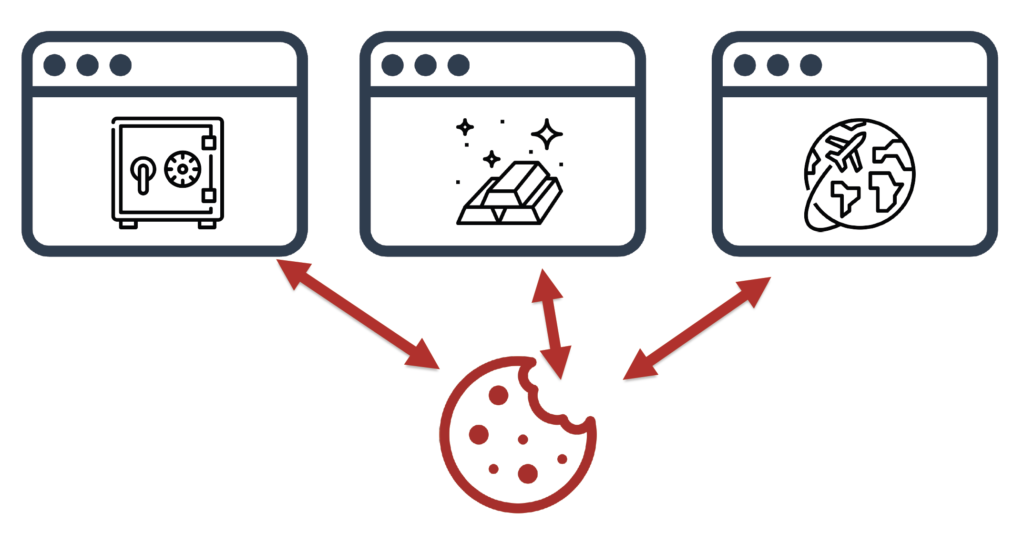
Teoretycznie takie możliwości daje 3rd party cookie, którego zawartość może być odczytana przez dowolną stronę i dowolny kod śledzący.
Powyższy przykład jest teoretyczny, ale dobrze ilustruje przyczyny, dla których 3rd party cookies znalazły się na cenzurowanym. Przeglądarki, w trosce o bezpieczeństwo użytkownika zaczęły blokować cross-site tracking, czyli śledzenie użytkownika na wielu stronach, w tym obsługę 3rd party cookies.
Dodatkową motywacją po stronie przeglądarek jest zamiar ochrony posiadanych danych i zapobieżenia korzystaniu z nich przez inne podmioty. Korzystaniu, co istotne ? bezpłatnemu.
Koniec 3rd party cookies
Uśmiercenie ciasteczek 3rd party stosunkowo łatwo przyszło w należącej do Apple przeglądarce Safari, której właściciel nie posiada znaczącego systemu reklamowego i która w ramach pakietu Intelligent Tracking Prevention zablokowała 3rd party cookie oraz wiele sposobów wykorzystania ciasteczek 1st party do śledzenia reklamowego. W efekcie, w Safari praktycznie nie oglądamy już reklam remarketingowych, jeśli nie jesteśmy zalogowani w środowisku Google, YouTube czy Facebooka.
Google, właściciel Chrome, znalazł się w trudnej sytuacji. Jego przeglądarka nie mogła pozostać tą, która ma najniższe standardy ochrony prywatności, a jednocześnie nie chciał pozbawić się dochodów z remarketingu, który stanowi istotną część wszystkich kampanii prowadzonych w sieci reklamowej Google.
3rd party cookie odpowiadają też za profilowanie użytkowników i emitowanie reklam opartych na zainteresowaniach oraz śledzenie konwersji po wyświetleniu reklamy.
Do śledzenia konwersji po kliknięciu prowadzącym na stronę docelową wystarczą cookie własne strony (1st party) ponieważ wszystkie niezbędne informacje dostępne są w obrębie witryny. Do śledzenia wyświetleń potrzebne są 3rd party cookies, ponieważ wyświetlenie reklamy ma miejsce na innej stronie, niż strona docelowa.
By wraz z ciasteczkami nie unicestwić remarketingu i innych funkcji reklamowych, firma Google przygotowała pakiet rozwiązań pod nazwą Privacy Sandbox, które pozwolą na zastąpienie 3rd party cookies w marketingu przy zachowaniu bezpieczeństwa i poszanowaniu prywatności użytkownika.
Rozwiązania te musiały zostać zaprojektowane tak, by nie faworyzowały technologii marketingowych Google, co mogłoby być uznane za praktykę monopolistyczną.
Protected Audience API, czyli remarketing
3rd party cookies grały kluczową rolę w remarketingu w sieci reklamowej Google oraz innych sieciach emitujących reklamy remarketingowe, jak np. Criteo czy RTB House.
W Privacy Sandbox za funkcję remarketingu odpowiada Protected Audience API.
Remarketing w tym rozwiązaniu jest realizowany na bazie historii odwiedzanych stron przechowywanej na urządzeniu (w przeglądarce).
- Podczas odwiedzin strony reklamodawcy (np. sklepu internetowego), kod remarketingowy zapisze w przeglądarce informację o potencjalnym zamiarze wyświetlania reklam przez tę stronę wraz z linkiem do danych o aktualnych stawkach oferowanych w kampanii remarketingowej.
- Gdy użytkownik odwiedzi stronę z powierzchnią reklamową (wydawcę), wyśle ona do przeglądarki listę współpracujących z nią sieci reklamowych i zapyta, czy przeglądarka nie chciałaby wyświetlić spersonalizowanych reklam z tych sieci.
- Przeglądarka sprawdza (przez wspomniane linki) aktualne stawki oferowane przez reklamodawców w tych sieciach, przeprowadza wewnętrzną aukcję i typuje reklamę do wyświetlenia.
- Następnie reklama wyświetlana jest w tzw. ogrodzonej ramce (fenced frame), do której zawartości nie ma dostępu strona, na której reklama jest wyświetlana.
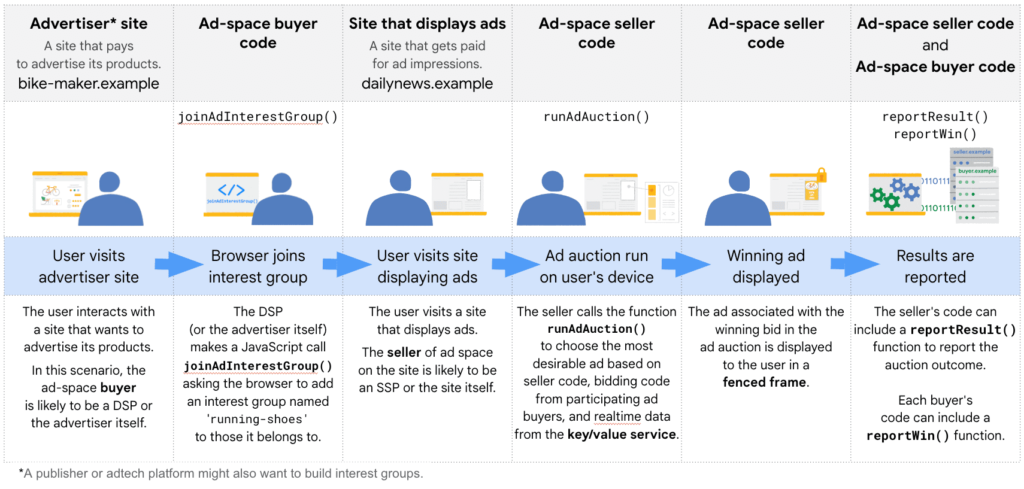
Dzięki temu remarketing działa, mimo że:
- Google (czy inny tracker) nie zbiera informacji o wszystkich odwiedzanych przez użytkownika stronach (nie profilują nas).
- Wydawca nie wie, czyje reklamy remarketingowe zostały wyświetlone konkretnemu użytkownikowi (inaczej sam mógłby w ten sposób profilować użytkowników).
Więcej na stronie Google Protected Audience API.
Topics API (reklama oparta na zainteresowaniach)
W dobie 3rd party cookies sieci reklamowe (np. Google) zbierały informacje o odwiedzanych przez nas stronach i na tej podstawie mogły budować, w zasadzie bez ograniczeń, nasz profil behawioralny. Następnie ? na bazie tych danych ? sieci reklamowe umożliwiały reklamodawcom kierowanie reklam na określone kategorie zainteresowań użytkownika.
Informację o naszej aktywności przekazywały do Google wyświetlane nam reklamy AdSense (reklamy Google) czy też osadzone na różnych stronach filmy YouTube (właśnie dlatego potrzebna jest zgoda na ich załadowanie). To, co pozwalało te informacje połączyć, to 3rd party cookie.
Teraz będzie się to odbywać inaczej. To nowe rozwiązanie nosi nazwę Topics API.
Analogicznie jak w przypadku remarketingu (Protected Audience API), informacje o zainteresowaniach użytkownika zbiera przeglądarka, a nie sieć reklamowa.
Lista możliwych do wykorzystania zainteresowań obejmuje kilkaset umiarkowanie szczegółowych kategorii, zdefiniowanych transparentnie w sposób czytelny dla człowieka i nie zawierających kategorii wrażliwych (zob. lista kategorii Topics API).
Topics API określa te zainteresowania na podstawie domeny odwiedzanej strony przez użytkownika strony. Dostępne są one wyłącznie dla tych sieci reklamowych, które zainicjowały zbieranie tych informacji poprzez skrypt danej sieci reklamowej wykorzystywany przez odwiedzane strony:
- Użytkownik odwiedza stronę, na której umieszczono kod sieci reklamowej. Zainteresowania użytkownika określone na podstawie domeny odwiedzanej strony zapisywane są w przeglądarce ?na prośbę? kodu sieci reklamowej znajdującego na danej stronie.
- Jeśli użytkownik odwiedzi stronę z powierzchnią reklamową obsługiwaną przez tę sieć reklamową, sieć ta będzie się mogła dowiedzieć o zapisanych PRZEZ SIEBIE zainteresowaniach użytkownika i wykorzystać to do wyświetlenia odpowiedniej reklamy.
Dostęp do zapisanych w przeglądarce zainteresowań jest jednak ograniczony do trzech kategorii, losowo wybranych spośród pięciu najważniejszych kategorii w zidentyfikowanych w każdym z trzech ostatnich tygodni (epok). Moment rozpoczęcia epoki dla użytkownika też jest losowy. To wszystko ma na celu uniemożliwienie identyfikacji użytkownika przez sieć reklamową na podstawie jego zainteresowań.
Dodatkowo, by jeszcze bardziej zmniejszyć ryzyko identyfikacji użytkownika, 5% zwracanych zainteresowań jest zupełnie losowa.
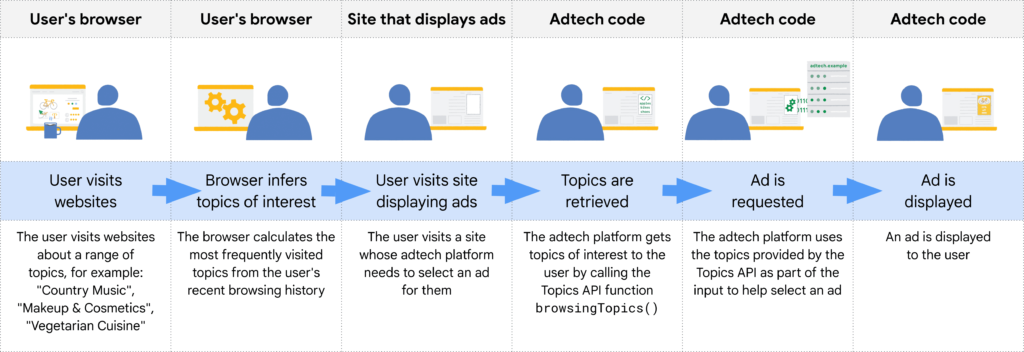
Innymi słowy:
Sieć reklamowa już nie będzie przechowywać szczegółowej historii odwiedzanych przez nas stron.
To przeglądarka będzie przechowywała informacje o dużym stopniu ogólności i udostępniać je w ograniczony, wybiórczy, losowy i nieznacznie zniekształcony sposób ? i to tylko tej sieci, która tę informację zapisała.
Użytkownik będzie miał kontrolę nad zapisanymi w przeglądarce i udostępnianymi przez nią informacjami, włączając w to możliwość całkowitego zablokowania tej funkcji.
Więcej o Topics API przeczytasz na stronach Google.
Attribution Reporting API (pomiar wyświetleń reklamy i konwersji)
Obok Topics API oraz Protected Audience API, warto odnotować jeszcze jedną ważna dla marketingu funkcję Privacy Sandbox: Attribution Reporting API.
Słowo „atrybucja” kojarzy się z modelami atrybucji. Tu chodzi jednak o sam pomiar skuteczności reklam poprzez wiązanie kliknięć i wyświetleń reklamy z konwersjami ? bez 3rd party cookies.
Attribution Reporting API udostępnia dwa rodzaje raportów:
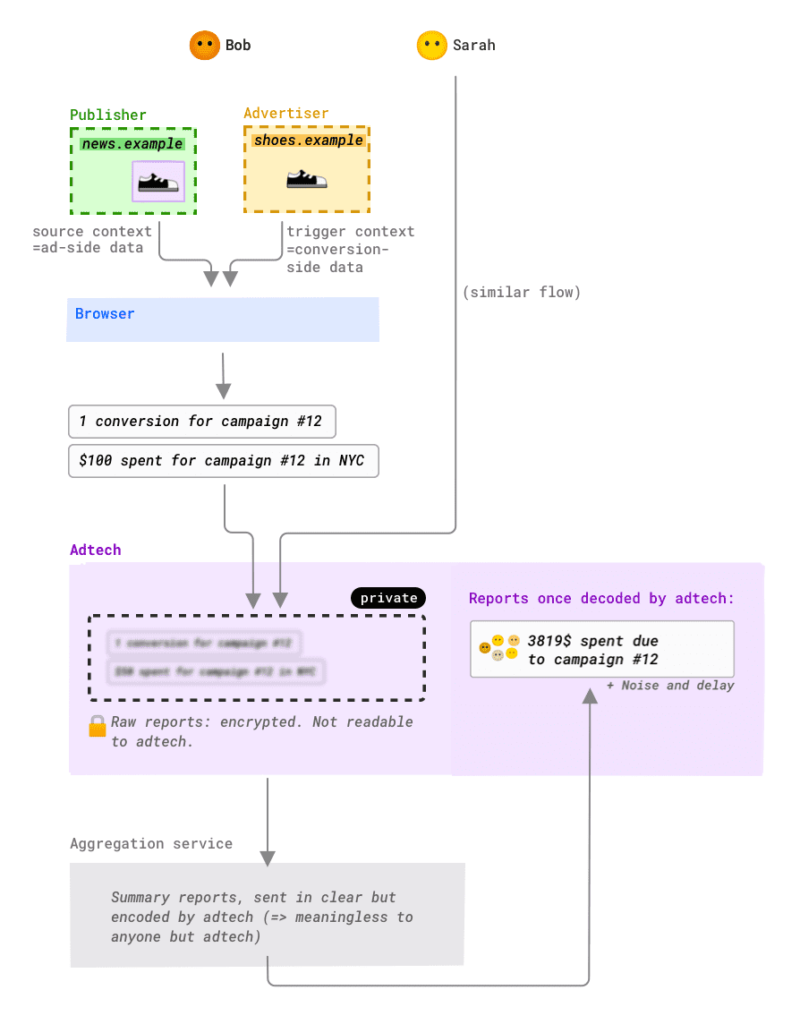
1. Raporty na poziomie zdarzenia (zob. ilustracja)
Identyfikator obejrzanej lub klikniętej reklamy (ID) zostaje zapisany w przeglądarce wraz z adresem domeny, na której oczekiwana jest konwersja.
Jeśli użytkownik skonwertuje, do systemu raportującego wysyłana jest informacja, że po wyświetleniu reklamy ID nastąpiła konwersja.
Dane o konwersji są ograniczone (max. 3 bity informacji), ponadto dodawane są do nich niewielkie zakłócenia i losowe opóźnienie. Celem takiego zniekształcania danych jest ograniczenie możliwości wykorzystania tych informacji do śledzenia użytkownika.
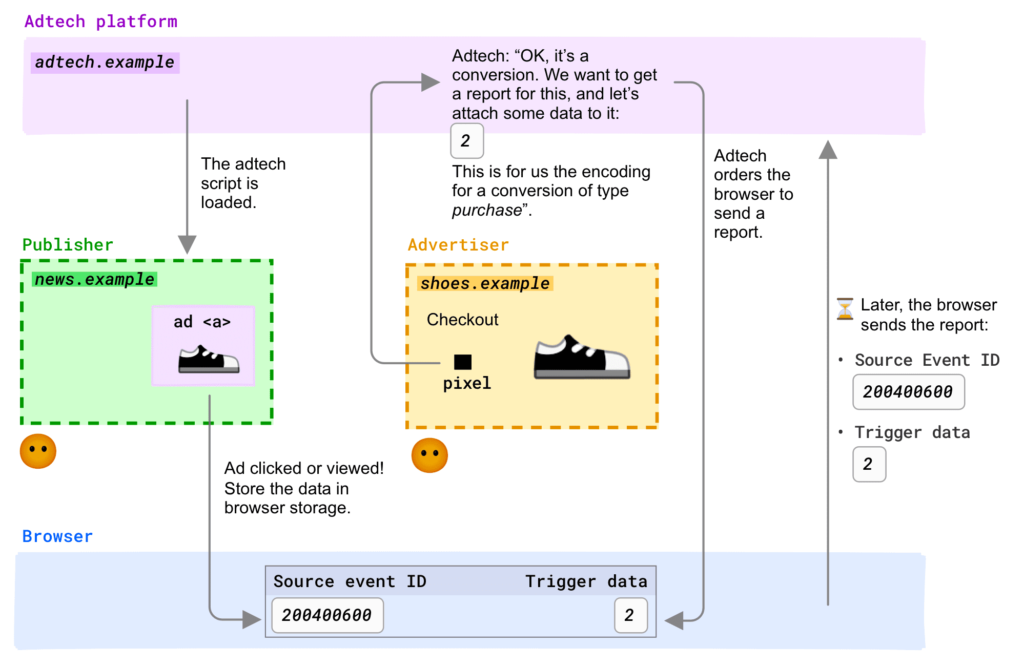
Przypomina to PCM (Private Click Measurement) firmy Apple, ale umożliwia również śledzenie wyświetleń.
2. Raporty podsumowujące
Raporty te nie obejmują ID reklamy, ale na jego podstawie przeglądarka uzyskuje dane np. o kampanii, grupie reklam itd. oraz informacje o konwersji (np. wartość transakcji) i PO ZASZYFROWANIU przesyła je do systemu raportującego.
System ten nie może tych zaszyfrowanych informacji odczytać i wysyła je do usługi agregującej w zaufanym środowisku wykonawczym, która agreguje dane i dodaje do nich zniekształcenia (np. zmienia wartość konwersji z 50,12 zł na 53 zł).
Zauważ, że wartość transakcji w połączeniu z jej datą (nawet przybliżoną) często pozwala na jednoznaczne zidentyfikowanie użytkownika. Zmniejszenie liczby unikalnych wartości transakcji ogranicza możliwość wykorzystania wartości transakcji jako identyfikatora.
Dzięki agregacji danych nie da się już uzyskać informacji o pojedynczym zdarzeniu. Im bardziej szczegółowe dane uzyskujemy o transakcji, tym mniej dokładne dane uzyskujemy o źródle. Im bardziej granularny jest raport dotyczący źródła, tym mniej szczegółów o samej konwersji uzyskamy.
[Przykład poglądowy] Możemy określić wartość danej transakcji i przypisaną do niej kampanię, ale już nie słowo kluczowe. W raporcie słowa kluczowego zobaczymy łączne przychody, ale już nie będą dostępne dane konkretnej transakcji.
Takie dane, po odszyfrowaniu, przesyłane są do systemu raportującego.
Co to oznacza?
Attribution Reporting API umożliwia powiązanie konkretnego kliknięcia reklamy z konwersją, na co nie pozwala PCM Apple. Dane o konwersji są jednak ograniczone i nie da się w nich zawrzeć danych osobowych (identyfikatora) lub szczegółów aktywności na stronie docelowej.
Dokładniejsze raporty są dostępne, ale łączenie identyfikatora kliknięcia i konkretnej konwersji (np. identyfikatora transakcji ecommerce związanej z danymi osobowymi nabywcy) nie jest możliwe.
Ma to na celu uniemożliwienie identyfikacji użytkownika i wykorzystanie systemu analitycznego jako furtki do śledzenia użytkownika między stronami (cross-site tracking).
Ceną płaconą za zwiększone bezpieczeństwo i prywatność użytkownika jest mniejsza precyzja raportowania. Na sygnał nakładany jest szum, a nie wszystkie informacje są dostępne, zwłaszcza te na wysokim poziomie granularności. Występuje opóźnienie raportowania, a raportowana data konwersji jest również przybliżona (niepewność rzędu 1-2 dni).
Czy to znaczy, że tak będzie wyglądała analityka przyszłości? I tak, i nie. Programy takie, jak Analytics, które w kontekście 1st party analizują źródła wizyt (w tym KLIKNIĘĆ reklamy) będą działać tak, jak dotychczas.
Do pomiaru konwersji po WYŚWIETLENIU reklamy lub zaangażowaniu poza stroną docelową ? czyli tam, gdzie potrzebny jest kontekst 3rd party ? po wyłączeniu 3rd party cookies systemy pomiaru będą musiały korzystać z Attribution Reporting API.
Więcej informacji na stronie Google o Attribution Reporting API.
Privacy Sandbox a zgoda użytkownika
A jak to wygląda w kontekście prawnym i wymogu zgody użytkownika?
Mimo wyeliminowania lub drastycznego ograniczenia przetwarzania danych osobowych, rozwiązania te raczej nie zwolnią z obowiązku uzyskania zgody użytkownika.
Przykładowo zobaczmy (w pewnym uproszczeniu), czym różni się ?stary? i ?nowy? remarketing realizowany przez Protected Audience API z punktu widzenia przetwarzania danych. Użyte w tym przykładzie ?Google? może oznaczać też Criteo, RTB House itd., a ?Onet? dowolnego wydawcę.
3rd party cookies
- Użytkownik odwiedza stronę Sklepu.
- Skrypt Google ze strony Sklepu zostawia w przeglądarce Użytkownika identyfikator w cookie (jeśli go tam jeszcze nie było).
- Skrypt Google raportuje do Google że przeglądarka Użytkownika (o danym identyfikatorze) odwiedziła stronę Sklepu.
- (Po jakimś czasie) Użytkownik odwiedza stronę Onetu, na której jest powierzchnia reklamowa Google.
- Skrypt Google na stronie Onetu odczytuje identyfikator z cookie i sprawdza, czy reklamodawcy nie chcą tej osobie wyświetlić reklamy.
- Google przeprowadza aukcję wśród reklamodawców zainteresowanych tym Użytkownikiem.
- Reklama, która wygra aukcję jest wysyłana na stronę Onetu (np. reklama Sklepu) i wyświetlana Użytkownikowi.
W konsekwencji:
- Na urządzeniu zapisywany jest identyfikator Użytkownika, który Google może czasem też powiązać z kontem tego Użytkownika w Google (stanowi dane osobowe).
- Google zbiera historię odwiedzanych przez Użytkownika stron i może go profilować.
- Onet widzi jakie reklamy ogląda i klika Użytkownik i może te dane gromadzić i profilować Użytkownika.
Protected Audience API
- Użytkownik odwiedza stronę Sklepu.
- Skrypt Google ze strony Sklepu zostawia w przeglądarce Użytkownika identyfikator reklamodawcy (Sklepu).
- (Po pewnym czasie) Użytkownik odwiedza stronę Onetu, na której jest powierzchnia reklamowa Google.
- Onet informuje przeglądarkę że jest zainteresowany wyświetleniem reklam Google.
- Przeglądarka sprawdza, jakie stawki oferują reklamodawcy od Google.
- Na podstawie stawek przeglądarka przeprowadza aukcję.
- Zwycięska reklama (np. Sklepu) jest wysyłana w odizolowanej ramce, do której Onet nie ma dostępu i wyświetlana Użytkownikowi.
W efekcie:
- Na urządzeniu zapisywany jest identyfikator powiązany z Google i reklamodawcą (nie stanowi danych osobowych).
- Google NIE ZBIERA historii odwiedzanych przez użytkownika stron.
- Onet NIE MOŻE zbierać historii oglądanych przez użytkownika reklam.
- Prywatność użytkownika jest chroniona: strony trzecie nie zbierają historii jego aktywności w sieci, ale reklamy wciąż za nim podążają.
W pewnym sensie, w Protected Audience API, podobnie jak Topics API, w miejsce przetwarzania danych użytkownika przez sieci reklamowe, mamy teraz z przetwarzanie danych sieci reklamowych przez użytkownika na jego urządzeniu. Można powiedzieć, że role się odwróciły.
Różnica jest więc taka, że nie dochodzi do przesyłania danych osobowych ? RODO nie stosuje się.
Zamiast ID użytkownika, w przeglądarce zapisywany jest identyfikator sieci reklamowej i reklamodawcy (odwiedzanej strony).
Na gruncie ePrivacy (prawo telekomunikacyjne) to jednak oznacza, że zgoda jest wymagana, bo identyfikator ten nie jest niezbędny do funkcjonowania strony.
Do podobnego wniosku doszedł też Lukasz Olejnik.
Related Website Sets
Jeśli świadczysz usługi na kilku domenach, warto zwrócić uwagę na inną funkcję Privacy Sandbox: Zestawy powiązanych witryn (Related Website Sets, RWS). Funkcja ta umożliwia stosowanie kontekstu 1st party na stronach utrzymywanych w różnych domenach i przekazywanie między nimi identyfikatorów tak, jak to umożliwiały 3rd party cookies.
Pozwala np. na przekazywanie zawartości koszyka zakupów lub informacji o zalogowaniu czy też przekazywanie statusu zgody lub danych do personalizacji treści pomiędzy takimi stronami tak, jakby były na jednej domen.
Więcej informacji na ten temat na stronach Google.
Co marketer powinien wiedzieć o Privacy Sandbox
Czy jako marketer musisz znać szczegóły działania tych technologii? Niekoniecznie. Ich adaptacja to przede wszystkim zmartwienie firm MarTech. Tak samo, jak kierowca nie musi znać zasady działania silnika samochodu.
Niemniej, wiedza na temat zasady działania (niekoniecznie szczegółów technicznych) tych rozwiązań może ułatwić ocenę ich zgodności z przepisami i odpowiednie opisanie sposobu przetwarzania danych np. w polityce prywatności.
Warto też wiedzieć, że Privacy Sandbox to również zestaw analogicznych rozwiązań dla systemu Android.
Poza opisanymi wyżej rozwiązaniami, Privacy Sandbox to również technologie pozwalające na obsługę osadzonych treści i funkcji, ochronę przez nadużyciami czy potwierdzanie tożsamości, które dotychczas wykorzystywały 3rd party cookies. Zainteresują one bardziej inżynierów budujących strony aplikacje web i mobile.
Adaptacja do tych rozwiązań to przede wszystkim zadanie dla sieci reklamowych i deweloperów, a reklamodawcy powinni przede wszystkim zadbać, by korzystali z aktualnych wersji skryptów i tagów śledzących i pozostałego oprogramowania analityczno-marketingowego. Zob. np. informacje dla użytkowników Campaign Managera.
Więcej informacji znajdziesz na stronie Privacy Sandbox.
