Przypisywanie całego udziału w konwersji jednej interakcji jest daleko idącym uproszczeniem. Na ścieżce użytkownika może pojawić się wiele interakcji i każda z nich potencjalnie może mieć większy lub mniejszy udział w doprowadzeniu do konwersji.
Poprzedni artykuł (cz. 7): Modele single-touch
Z tego powodu w modelowaniu atrybucji, obok modeli single-touch wykorzystuje się modele, które mogą uwzględniać wszystkie interakcje, które wystąpiły na ścieżce: modele multi-touch.
Najważniejsze modele multi-touch
Opisane poniżej modele zostały wycofane z Google Ads i Analytics w 2023 roku. Więcej o atrybucji w Analytics w tym artykule. Aktualnie (styczeń 2024) modele te mają wciąż zastosowanie w innych narzędziach modelowania atrybucji, np. Campaign Manager i Search Ads 360 (Google Marketing Platform).
Aktualnie (styczeń 2024) jedynym dostępnym w Google Ads i Analytics modelem multi-touch jest algorytmiczny model oparty na danych.
Oto najważniejsze heurystyczne modele atrybucji:
Model liniowy
Liniowy model atrybucji (linear model) przypisuje każdej interakcji jednakową wagę, czyli „każdemu po równo”. W przypadku pięciu interakcji na ścieżce, każda otrzyma po 20% udziału.

Model liniowy może być bazowym modelem do tworzenia bardziej zaawansowanych modeli.
Model uwzględnienia pozycji
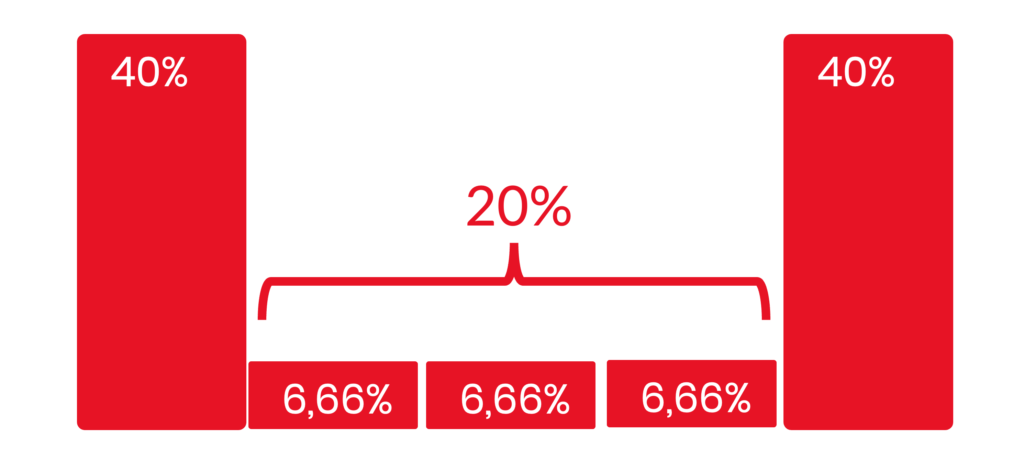
Model uwzględnienia pozycji (position based) przypisujący określoną wagę: pierwszej interakcji, ostatniej interakcji i łącznie wszystkim pozostałym (środkowym) interakcjom. Oto jak wygląda atrybucja w przypadku modelu 40/20/40:
Innym typowym modelem jest 30/40/30, ale tak naprawdę można sobie wybrać dowolny podział pozycji, jeśli model umożliwia dostosowanie.
Model rozkładu czasowego
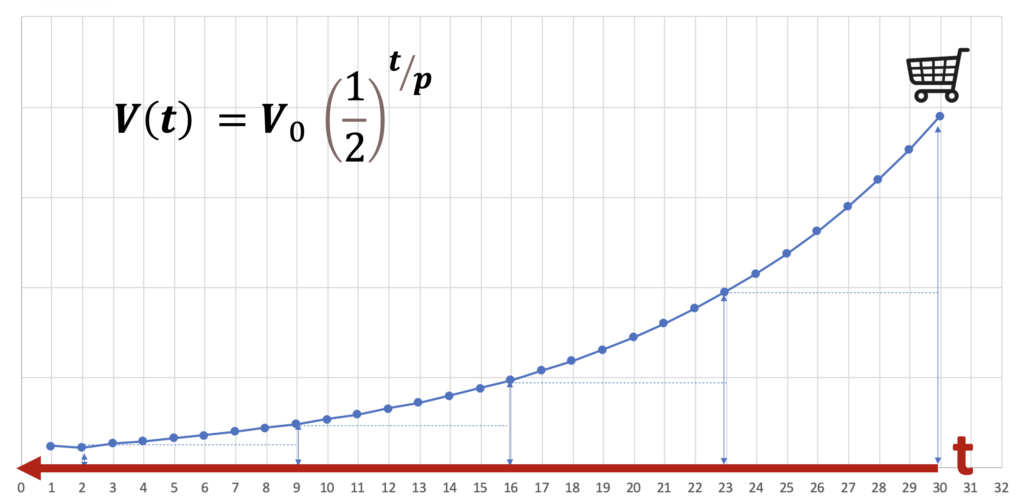
Model rozkładu czasowego (Time Decay) przypisuje interakcjom wagi tym mniejsze, im dłuższy okres upłynął od interakcji do konwersji. Wykorzystuje on formułę połowicznego rozpadu, tę samą, która opisuje rozpad pierwiastków promieniotwórczych.
W formule na ilustracji wartość V(t) zależy od upływu czasu, gdzie stałe V0 to wartość początkowa, a p to okres połowicznego rozpadu. Zwróć uwagę, że oś czasu skierowana jest w lewo:
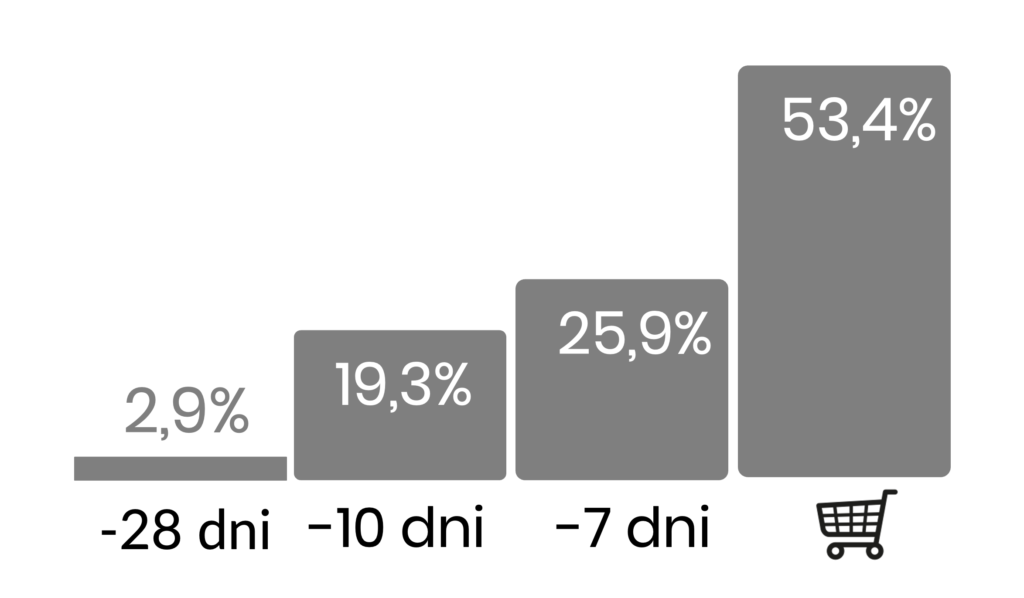
Przy okresie połowicznego rozpadu 7 dni, dla czterech interakcji, atrybucja będzie wyglądała następująco (ostatnia interakcja znajduje się po prawej stronie):
Okres połowicznego rozkładu jest parametrem, który można modyfikować. Bardzo długi okres połowicznego rozpadu przybliża ten model do modelu liniowego, bardzo krótki okres połowicznego rozpadu spowoduje, że model ten będzie zbliżony do modelu ostatniej interakcji.
Istnieje też odwrotny model rozkładu czasowego (lustrzane odbicie), w którym największa wartość przypisana jest pierwszej interakcji. W takim modelu bardzo krótki okres rozpadu sprowadzi ten model do modelu pierwszej interakcji.
Opisane poniżej funkcje stosowane były w poprzedniej wersji Google Analytics (Universal Analytics) i obecnie (styczeń 2024) nie są dostępne w Analytics (GA4). Aktualnie w analogiczny sposób działają funkcje atrybucji w Campaign Managerze (Google Marketing Platform).
Zdefiniowane w systemie, powyższe modele bazowe można modyfikować, określając ich własne okno konwersji oraz zmieniając wagi przypisywane interakcjom, na przykład:
- Ustalając własne okno konwersji (okres ważności, lookback window);
- Stosując niestandardowe reguły kredytowe, które pozwalają modyfikować wagę przypisywaną określonym interakcjom w stosunku do wagi wynikającej z modelu bazowego, w zależności od rodzaju interakcji i pozycji na ścieżce;
- Dostosowując wagę interakcji na podstawie zaangażowania związanego z tą interakcją: czasu spędzonego w witrynie lub głębokości wizyty (liczby stron na daną wizytę).
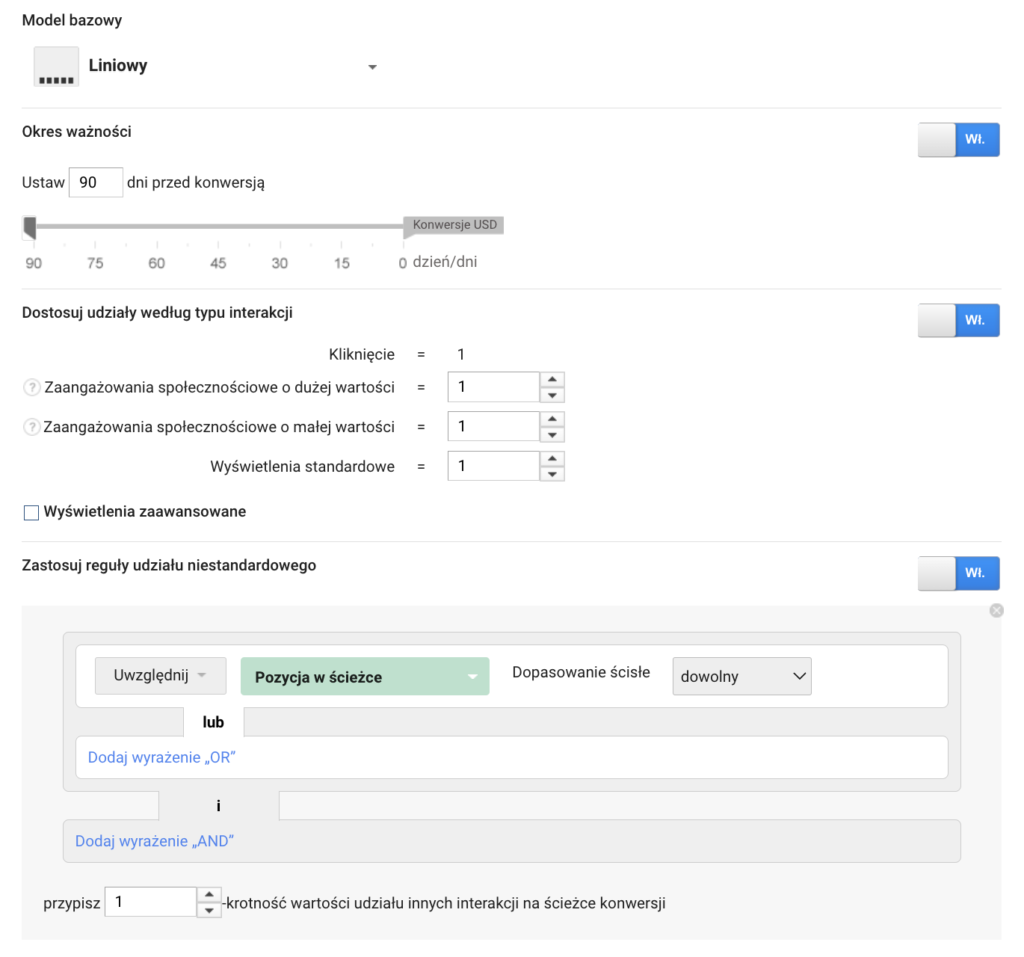
Konkretne możliwości dostosowania zależą od danego systemu modelowania atrybucji. Informacje o konfiguracji niestandardowych modeli można znaleźć np. w artykule pomocy Campaign Managera na temat niestandardowych modeli atrybucji. Poniżej kilka praktycznych uwag związanych z wykorzystywaniem tych modeli:
- Stosując niestandardowe reguły kredytowe należy pamiętać, że ?kredyt pomnożony X razy przez inne interakcje na ścieżce konwersji? (patrz ilustracja powyżej) oznacza modyfikację wagi danej interakcji z uwzględnieniem innych reguł modelu. Liczba ?X? stanowi więc mnożnik, który zwiększy wagę danej interakcji w stosunku do wagi, którą ta interakcja by miała, gdyby dana reguła niestandardowa nie została zdefiniowana.
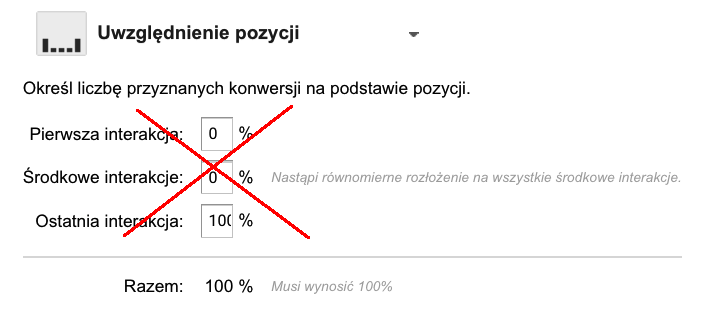
- W domyślnym modelu uwzględniania pozycji, zarówno pierwszej, jak i ostatniej interakcji przypisywane jest po 40% udziału w konwersji, czyli łącznie pierwsza i ostatnia interakcja mają 80% udziału, a pozostałe 20% udziału przypisywane jest po równo środkowym interakcjom. Jeżeli na ścieżce występują tylko dwie interakcje, to udział przypisany w definicji środkowym interakcjom zostanie rozdzielony po połowie pomiędzy pierwszą i ostatnią interakcję ? w modelu domyślnym będą więc miały one udział po 50% każda.
Udział przypisany środkowym interakcjom zostanie przypisany po połowie pierwszej i ostatniej interakcji również jeśli będą one miały zdefiniowane różne udziały, np. w modelu, w którym 20% udziału ma pierwsza interakcja, 50% ? ostatnia interakcja, a 30% udziału mają interakcje środkowe, w przypadku jedynie dwóch interakcji na ścieżce interakcja pierwsza otrzyma 20% + 30%/2 = 35%, a interakcja ostatnia otrzyma 50% + 30%/2 = 65% udziału w konwersji.
- Jeśli na ścieżce występuje tylko jedna interakcja, otrzyma ona 100% udziału w konwersji, niezależnie od jakichkolwiek warunków.
- Wagi przypisywane pierwszej, ostatniej i środkowym interakcjom w modelach uwzględniania pozycji można modyfikować. Wagę 0% należy stosować ostrożnie, zwłaszcza jeśli chcemy stosować dodatkowe reguły niestandardowe. Interakcje, którym przypiszemy wagę zero, nie będą się tym regułom już w żaden sposób poddawały (udział o wartości 0% pomnożony przez nawet bardzo duży mnożnik wciąż będzie wynosił 0%). W szczególności, nie ma większego sensu przypisywanie wartości 0% interakcjom środkowym i jednocześnie 0% pierwszej albo ostatniej interakcji, gdyż wtedy 100% udziału w konwersji zostanie przypisane odpowiednio ostatniej bądź pierwszej interakcji, a jakiekolwiek dodatkowe reguły niestandardowe będą tu nieskuteczne (innymi słowy, modele takie zadziałają tak samo jak domyślne modele odpowiednio ostatniej lub pierwszej interakcji, bez możliwości ich modyfikowania).
- Podobnie, z ostrożnością należy stosować wagi ?0? (zero) w dodatkowych regułach niestandardowych. Jeżeli na skutek kombinacji warunków wszystkim interakcjom na ścieżce miałby być przypisany zerowy udział w konwersji, wtedy całość udziału w konwersji zostanie przypisana bezwzględnie ostatniej interakcji, niezależnie od zastosowanego modelu. Jeśli chcemy, by jakaś interakcja była ignorowana, lepiej przypisać jej bardzo niską wagę, np. 0,00000001.
- Bardzo niskie, ułamkowe wagi pozwalają tworzyć „reguły awaryjne” analogiczne do tych stosowanych w modelach single touch. Przykładowo, jeśli nie chcemy, by wejścia bezpośrednie i wizyty z organic otrzymały udział w konwersji, ale w wypadku, gdy na ścieżce mamy tylko direct i organic chcemy by przypisało wartość do organic, wtedy możemy zastosować np. wagę 0,00000001 do direct i wagę 0,00001 do organic.
- Modele multi-touch rozdzielają udział w każdej konwersji pomiędzy wiele źródeł, przypisując im ułamek udziału w konwersji. Z tego powodu w raportach porównania modeli atrybucji konwersje mogą mieć wartość ułamkową, a w raportach opartych na pierwszej/ostatniej interakcji zobaczymy konwersje z dwoma zerami po przecinku.
Obecnie (styczeń 2024) w Google Analytics wszystkie modele, w tym modele multi-touch są modelami niebezpośrednimi (non-direct), czyli unikają przypisania konwersji wizytom bezpośrednim. Przypisanie konwersji do wizyt bezpośrednich następuje tylko w przypadku, gdy na ścieżce nie ma innych interakcji niż direct.
Modele algorytmiczne
Osobną klasę modeli multi-touch stanowią modele algorytmiczne, w których reguły przypisania są określane przez algorytm i rzecz jasna, nie da się przedstawić ich definicji w prosty sposób. Producenci oprogramowania zazwyczaj nie zdradzają szczegółów działania tych algorytmów.
Dostępne są biblioteki (np. w Pythonie lub R), które umożliwiają tworzenie algorytmicznych modeli atrybucji wykorzystujących m.in. łańcuchy Markowa lub wartość Shapleya.
Następny artykuł (cz. 9): Model oparty na danych (Data-driven).
Warto przeczytać: Przewodnik po atrybucji w Google Analytics
